论文简介
这篇论文发现当前的BERT是没有充分训练的,如果经过好好调参的话,BERT是可以比后BERT时代的模型效果要好的。而且由于训练是很耗费资源和时间的,所以很多预训练模型都无法进行系统的比较。
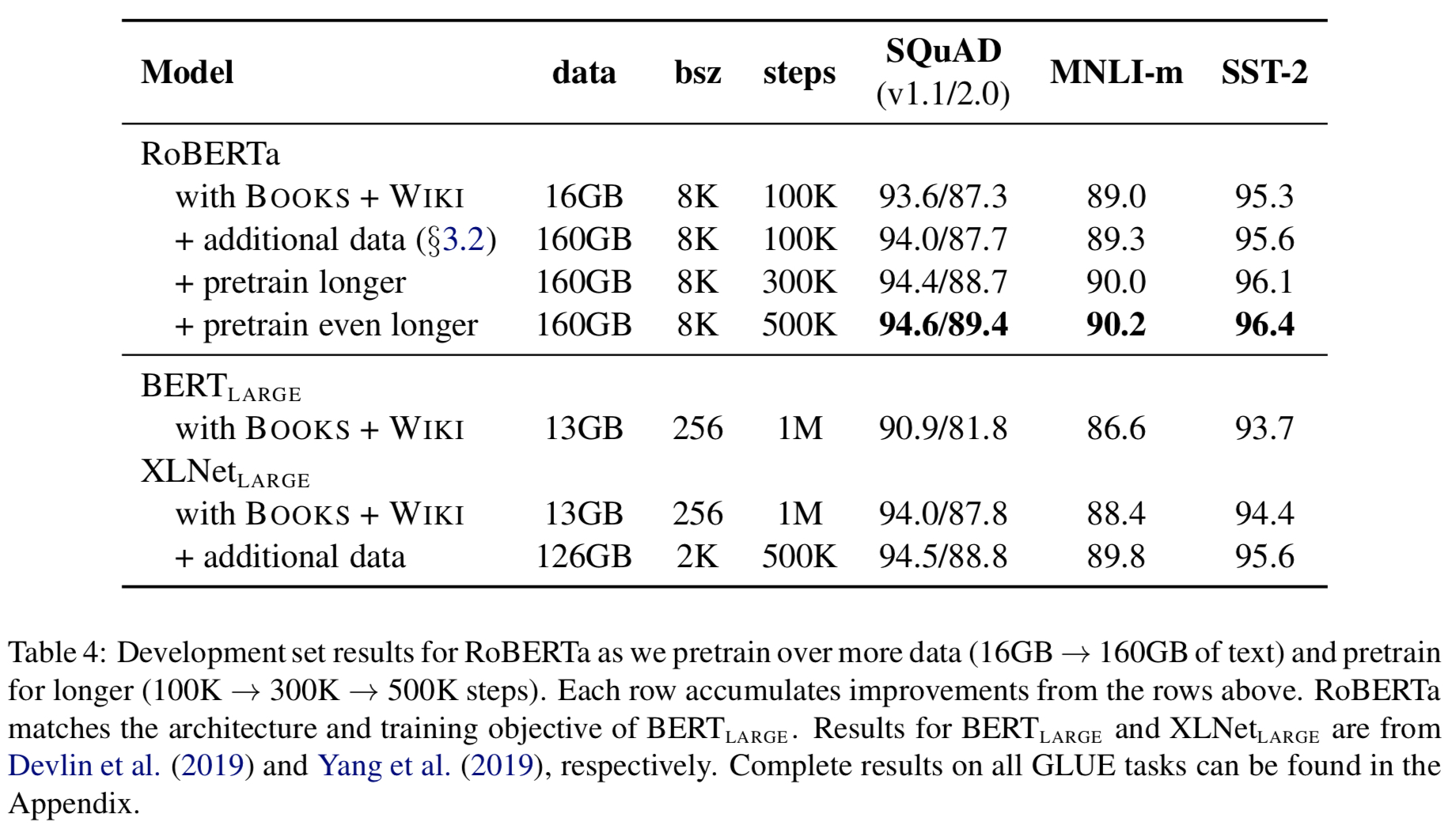
本论文对于BERT的改进主要有以下几点:1、在更多数据上进行更长时间的训练,同时采用更大的batch;2、去除NSP任务;3、在更长句子维度上进行训练;4、在训练过程中动态调整mask。同时收集了一个新的数据集(CC-NEWS)。
BERT介绍
MLM任务,随机选择15%的token进行mask,其中80%替换为MASK,10%保持不变,10%替换为别的token。在BERT中是在整个预训练的数据集中重复10次,即相当于生成10倍的训练样本,保存之后在后面的训练过程中就保持不变了。
NSP任务,预测输入的两个句子在原文中是不是上下文的关系。
原BERT的参数设置
- 采用Adam优化器,$beta_1=0.9, beta_2=0.999, \varepsilon=1e-6$,学习率采用的是warm up策略,前10000个 step达到峰值1e-4,后面再递减
- 所有层的dropout都是0.1
- 模型训练1000000个step,batch为256,句长为512
本文复现BERT的参数设置
- 根据具体设置调整了峰值学习率和warmup步数
- 训练过程对Adam优化器的$\varepsilon$参数非常敏感
- 在batch比较大的情况下,设置$beta_2=0.98$有利于提高训练稳定性
- 训练BERT的时候前90%的时间是采用较短的句长???(但是在bert源码中没看到这部分代码,只是在生成mask训练样本的时候,会有10%生成较短的文本,代码给出的解释是为了使bert在短文本问题中也能使用,而不会受限于512的文本长度)。在本文中均采用512长度的文本进行训练
论文改进
动态掩码和静态掩码
BERT是在训练之前就已经将训练数据处理好了,本论文是在训练过程中对数据进行mask,从结果来看动态掩码效果有提升,但不是很明显。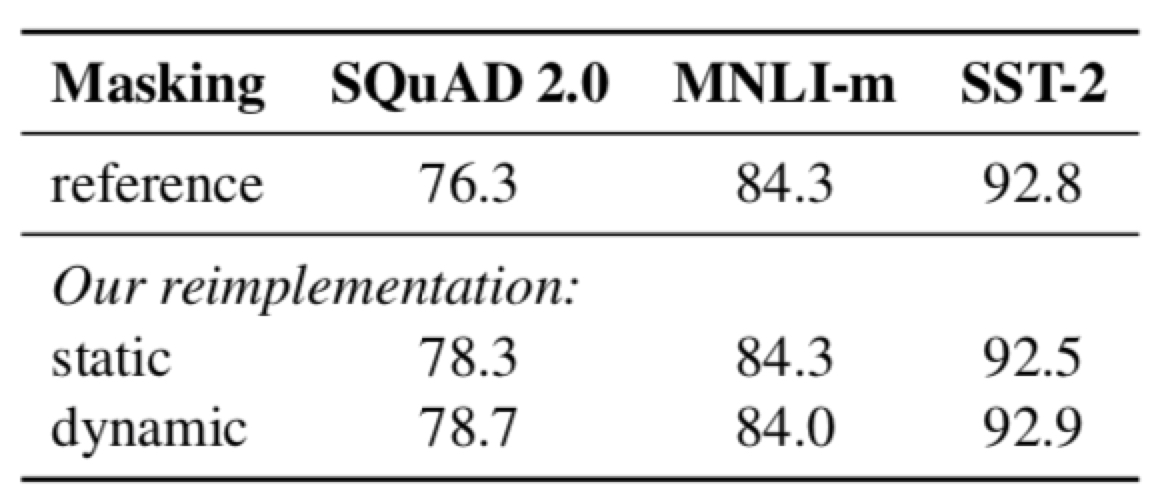
不同文档分割方式和NSP任务
分为四种情况进行实验:
- SEGMENT-PAIR+NSP:来自于一个或两个文档的多个句子组成总的输入,和原有的BERT论文一致
- SENTENCE-PAIR+NSP:来自于一个或两个文档的单个句子,句子级别的
- FULL-SENTENCES:来自于多个文档的句子,不同文档的句子之间用符号分隔,没有NSP
- DOC-SENTENCES:来自于当个文档的句子,没有NSP
具体的结果如下:去除NSP任务后,效果有所提升;采用同个文档的训练效果比较好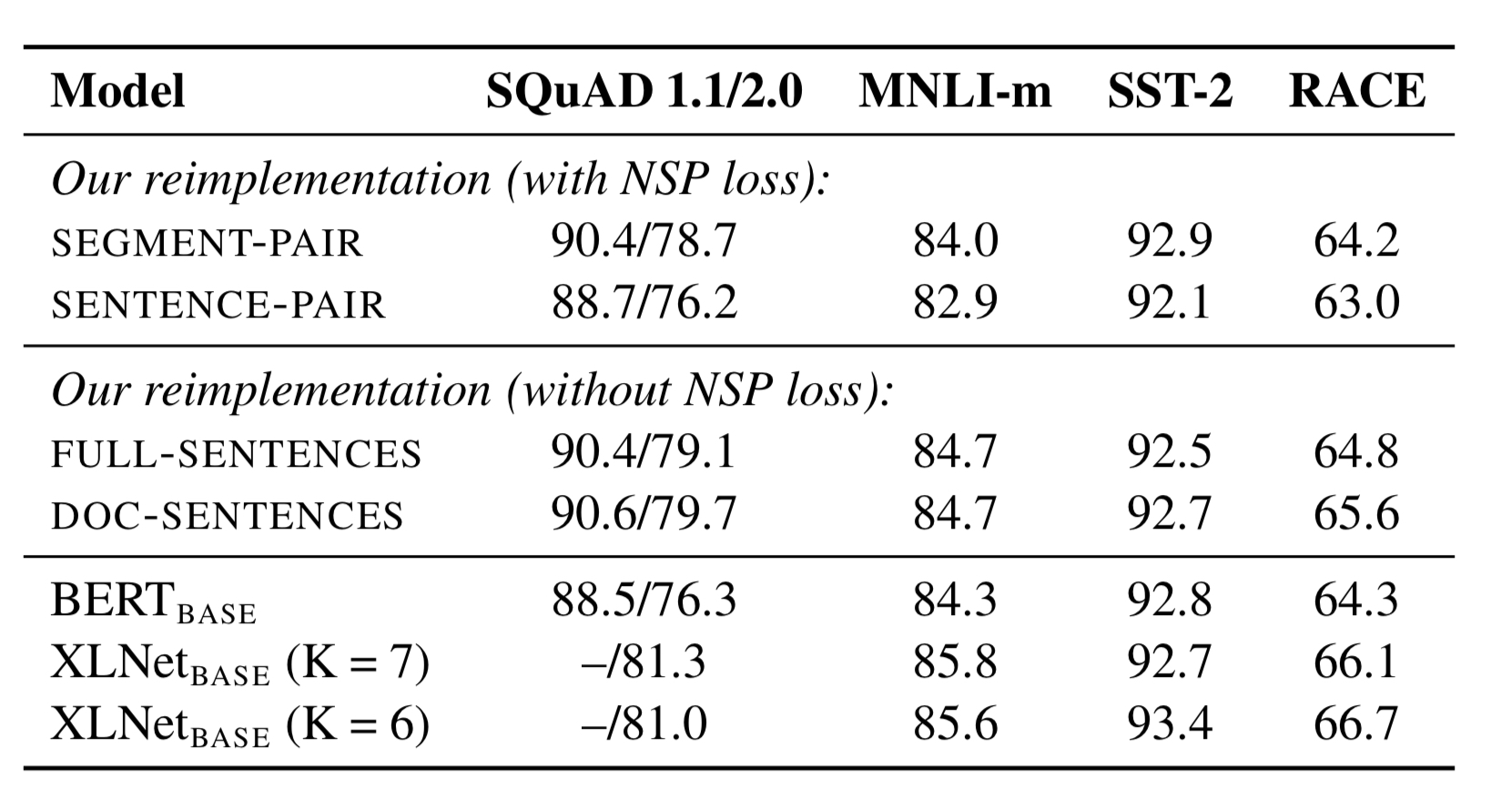
训练采用更大的batch_size
相比于BERT采用256的batch_size,本论文实验了更大的batch的影响,同时控制了模型对每个训练样本的利用次数是一致的,发现采用更大的batch,同时提高学习率,可以在一定程度提升模型效果。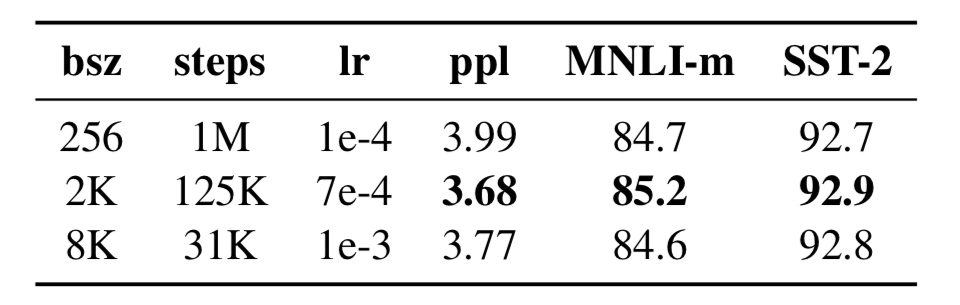
文本编码方式
采用byte-level的BPE代替character-level的BPE
总结
在进行实验的时候,主要把以上四个方面给加入到模型中,主要是:动态掩码;去除NSP;大batch;byte-level的BPE。同时还实验了预训练数据集的大小和每个样本的训练轮数。结果表明更多数据和更长的训练时间可以提高模型效果(得到的结论都是符合直观理解的)。