论文简介
在预训练的时候,通过增大模型大小可以有效提升模型在下游任务的表现,但是模型大小会受到GPU/TPU内存大小和训练时间的限制。为了解决这些问题,我们提出了两个降低模型参数的方法来降低BERT的内存占用以及提升训练速度。实验表明我们模型比原有BERT模型规模更小,同时我们使用了自监督损失来建模句子内部的相关性,能够有效提升模型在具有多个句子输入的下游任务的效果。在具有更少参数的情况下,我们的模型在多个任务建立了SOTA的效果。
待解决的问题和方法
本文在原有的BERT的基础上增加了一倍的隐藏层大小,从1024增加到2048,但是从实验结论上来看,模型效果反而下降了,说明单纯增加模型参数并不能提升模型效果。为了在不改变模型结构的条件下减少模型参数,并提升训练速度,本文提出了两种方法。
- 对词向量大小进行因式分解,将隐层大小和词向量大小解耦合
- 跨层参数共享
- 采用SOP(sentence-order prediction)任务代替NSP任务
通过上面两种方法还有正则的效果,并提升了模型训练的稳定性。
ALBERT
参数说明
词向量表示大小$E$,编码层数目$L$,隐藏层大小$H$,前向层大小$4H$,attention头数$H/64$。
词向量矩阵因式分解
在BERT,RoBERTa和XLNet中,词向量的大小$E$和隐藏层大小$H$是一样的,但是这个方法会有以下两个问题。
- 词向量的大小$E$学习到的是上下文无关的表示,隐藏层大小$H$学习到的是上下文相关的表示,而对于BERT来说模型的能力主要来源于上下文的表示,所以$H$一般有比较大的值,所以将$E$和$H$解耦合能够有效降低参数量
- 在实际应用中,模型的词表大小$V$一般都很大,如果$E$的值也比较大的话,那么整个词向量矩阵大小为$V*E$,参数量将非常大,在更新的时候大多数参数都会很少被更新。
基于上面的理由,我们将词向量映射到较小的$E$,然后再映射到$H$,这样就可以打破$E \equiv H$的限制,词向量矩阵的大小从$O(V \times H) $降低到$O(V \times E+E \times H)$,其中$H \gg E$。本质上就是在降低了词向量的大小,然后加上一层全连接层将维度映射到$H$。
参数共享
根据transformer的结构,参数共享可以包括以下几种:1、共享FFN的参数;2、共享attention层的参数;3、同时共享FFN和attention层参数。
同时还比较了BERT和ALBERT输入和输出之间L2距离和cos距离,结果表明在ALBERT中,层与层之间的输入、输出转换更加光滑。
SOP任务
在BERT中除了采用MLM任务,还加入了NSP任务,该任务是判断两个句子是否是连贯的两个句子,正样本是同个文档里连贯的两句话,负样本是从两个不同的文档中分别抽取的句子。有几篇论文讨论了NSP任务的有效性,发现去除NSP任务之后模型效果反而会有提升。
本论文认为NSP任务之所以没有效果是因为这个任务太简单了,这个任务选取了两个不同文档的句子作为负样本,这样就同时为该任务引入了文档主题信息,而主题分类的任务比句子连贯性的任务要简单得多。所以NSP任务并没有起到原有的效果。(而BERT论文在进行消融实验的时候发现NSP任务还是有效果的,RoBERTa论文中认为有可能是在进行消融实验的时候只把NSP任务去除了,但是有部分训练语料的句子对还是随机在两个文档中获取到的,导致效果会降低)
为了解决NSP过于简单的问题,论文中提出了SOP任务,即预测两个句子的顺序是否正常。正样本的产生方法还是和BERT一样,在产生负样本的时候,还是从同个文档中获取到连续的两个句子,然后颠倒两者的顺序。从这可以看出,SOP任务避免引入了主题信息,使模型更加注重于学习句子的连贯性。而且SOP任务训练出来的模型可以在一定程度上解决NSP任务,但是NSP任务却无法解决SOP任务。
实验
1、本论文采用了n-gram掩码,n大小按照以下公式进行选择,n最大为3。
$$p(n) = \frac{\frac{1}{n}}{\sum_{k=1}^N\frac{1}{k}}$$
2、在进行模型大小调整的时候,主要调整的是宽度而不是深度。
3、从下面结果可以看出来如果只是采用参数共享,不增加模型大小的话,ALBERT的效果是不如BERT的。 但是通过增加层数和隐层大小,ALBERT在保持参数量低于BERT的前提下,在各个任务上可以得到更优的效果。
由于模型整体结构并没有大改变,ALBERT对于训练速度和推理速度并没有明显提升,只是降低了参数量。(在实验ALBERT和BERT的时候,同样的结构大小,同样的数据,ALBERT训练30个epoch,batch大小为64,,每个样本大约耗时2ms,训练时间为11个小时。BERT训练50个epoch,batch为大小128,每个样本大约耗时2.2ms,训练时间为22个小时。说明ALBERT的训练数据有所提升,但不是很明显)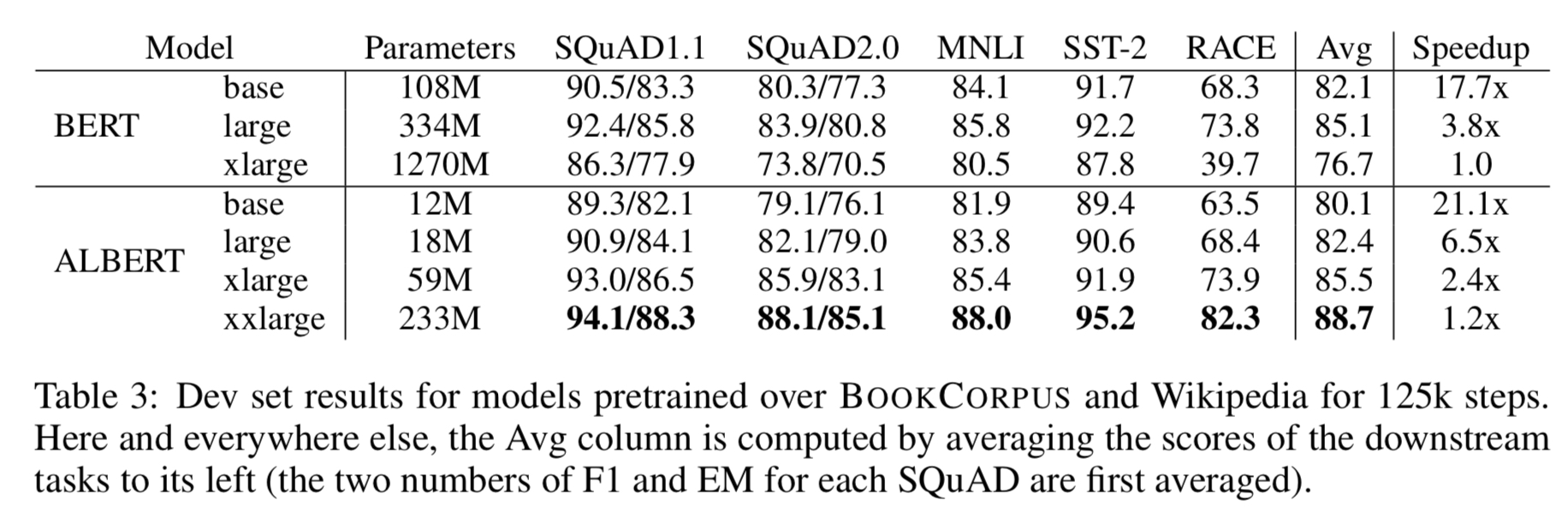
4、在没有进行参数共享时,词向量大小$E$越大,模型效果越好;但是在参数共享的条件下,$E=128$时效果最佳。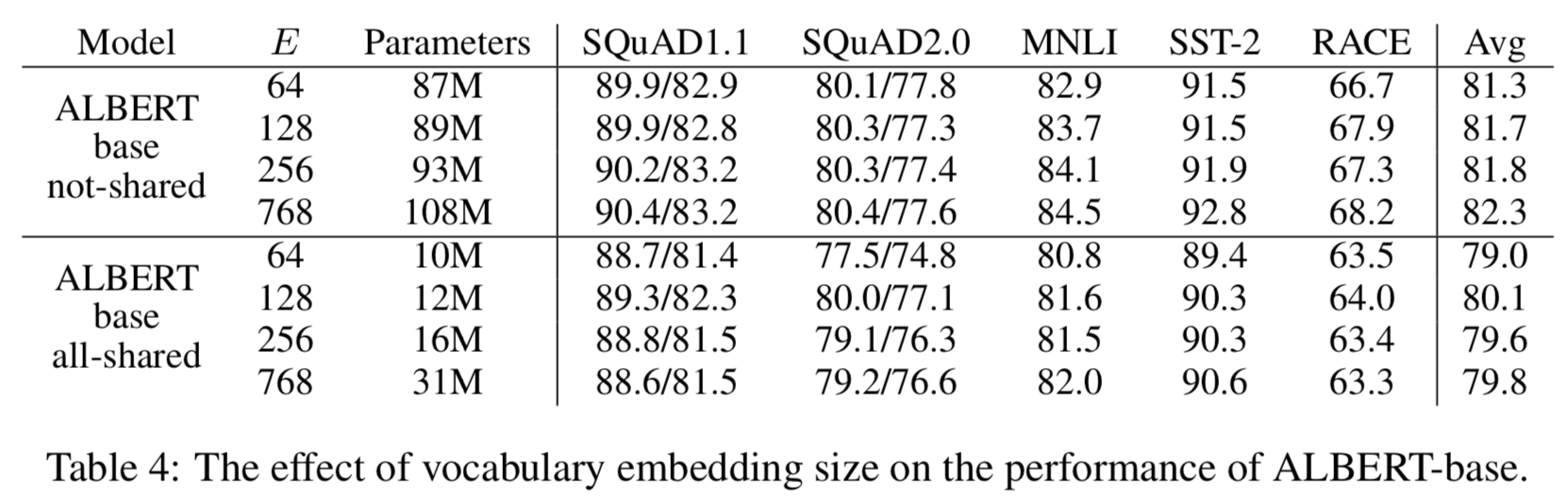
5、参数共享对模型效果有损伤,而且这损伤主要来源于FFN参数的共享,attention层参数的共享损伤较少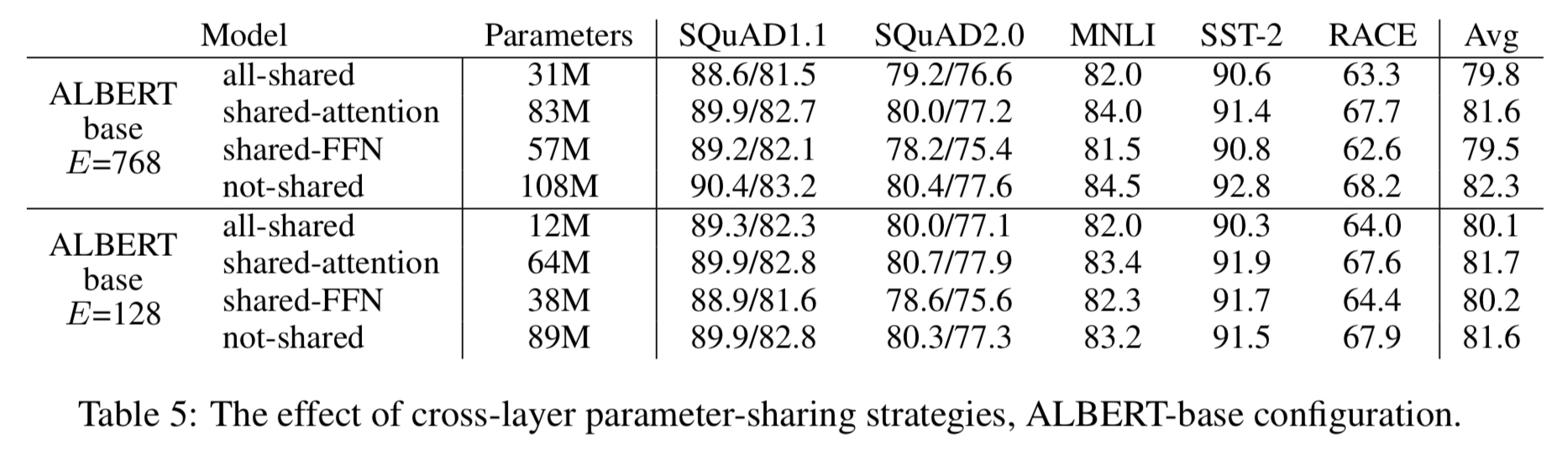
6、NSP任务对模型效果提升很小,SOP任务对模型效果提升很大
7、实验了不同深度和宽度的ALBERT,发现不断加大深度和宽度并不能一直提升模型效果,在后面效果会有个下降的过程。其实这应该也是可以理解的,当模型深度和宽度不断增加的时候,模型的训练难度也会增加。
8、同等的训练时间,ALBERT-xxlarge比BERT-large在平均准确率上仍然有1.5%的提升
9、去除dropout对模型效果有提升。